CsvHelper vs Sep in the land of bad CSVs
Periodically I see following tweet where author of Sep praises it for being the fastest .NET CSV parser. And rightly so, it’s super fast, and works great. If your CSVs are well formed.
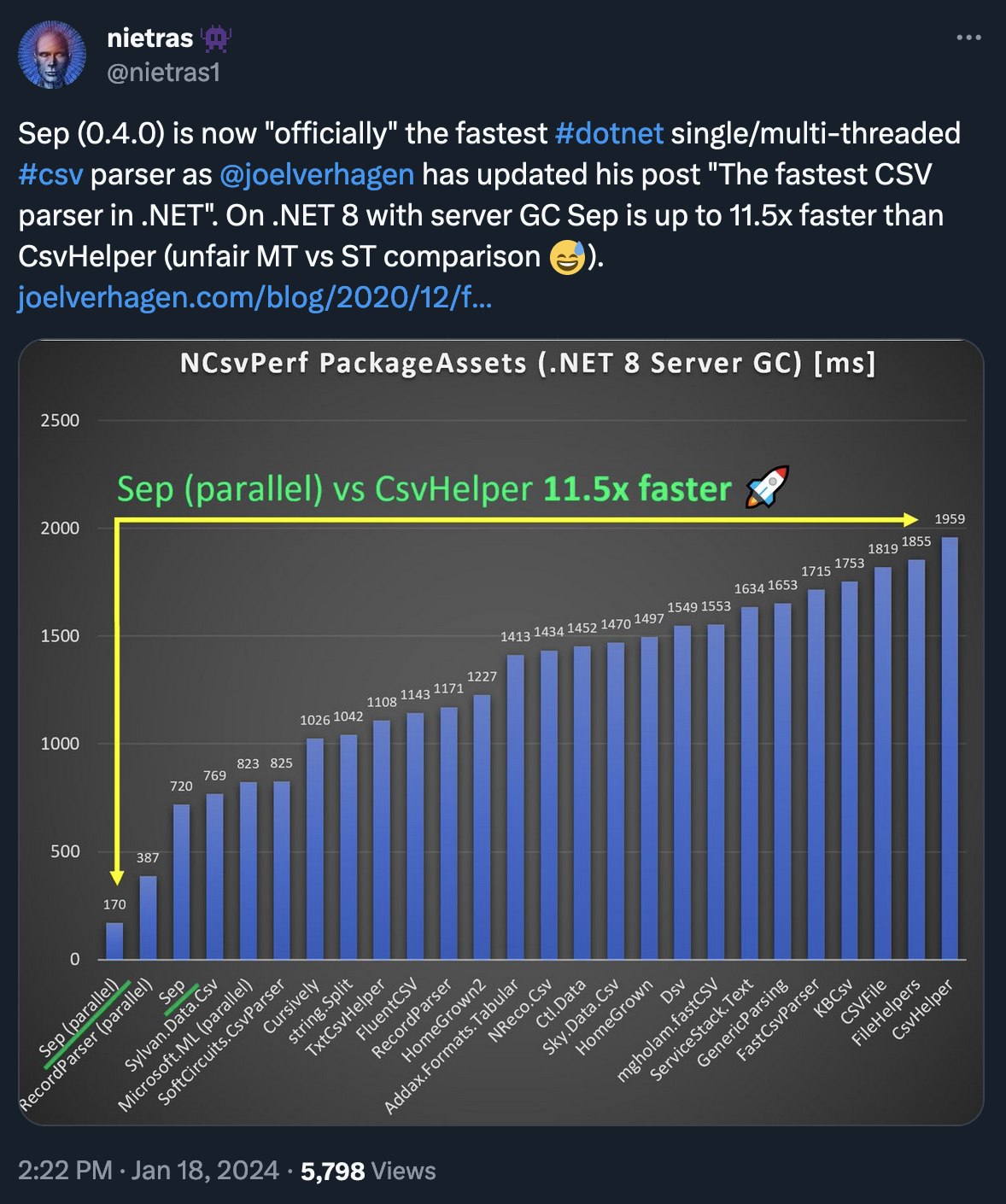
I’ve allowed myself to retweet the above with a comment:
It’s fast alright. And nice to use, although not so easy as CSVHelper. So, if you have these perfect CSVs (author claims Sep is relaxed on standard, but in reality not so much) I can fully recommend it. However, if you’re receiving a broken CSV/TSV files, CSVHelper is better.
It’s started a discussion with the author where he’s pointed out providing ORM functionality wasn’t his goal. And I get it, and totally agree. However, he’s not addressed my claim that Sep isn’t so good if CSV isn’t well formed. Well, maybe I wasn’t very explicit about it, so I’ll explain it now.
On Sep’s ReadMe there’s a section Unescaping where author explains how Sep handles broken CSV quotes in comparison to other CSV parsing libraries. There’s also our CsvHelper in two modes, standard and with BadDataFound = null. Sep is presented with Unescape = true in SepReaderOptions. But CsvHelper has third mode, Mode = CsvMode.NoEscape, which basically accepts anything, and provides it as-is. It’s like Excel, which can read really bad delimited files.
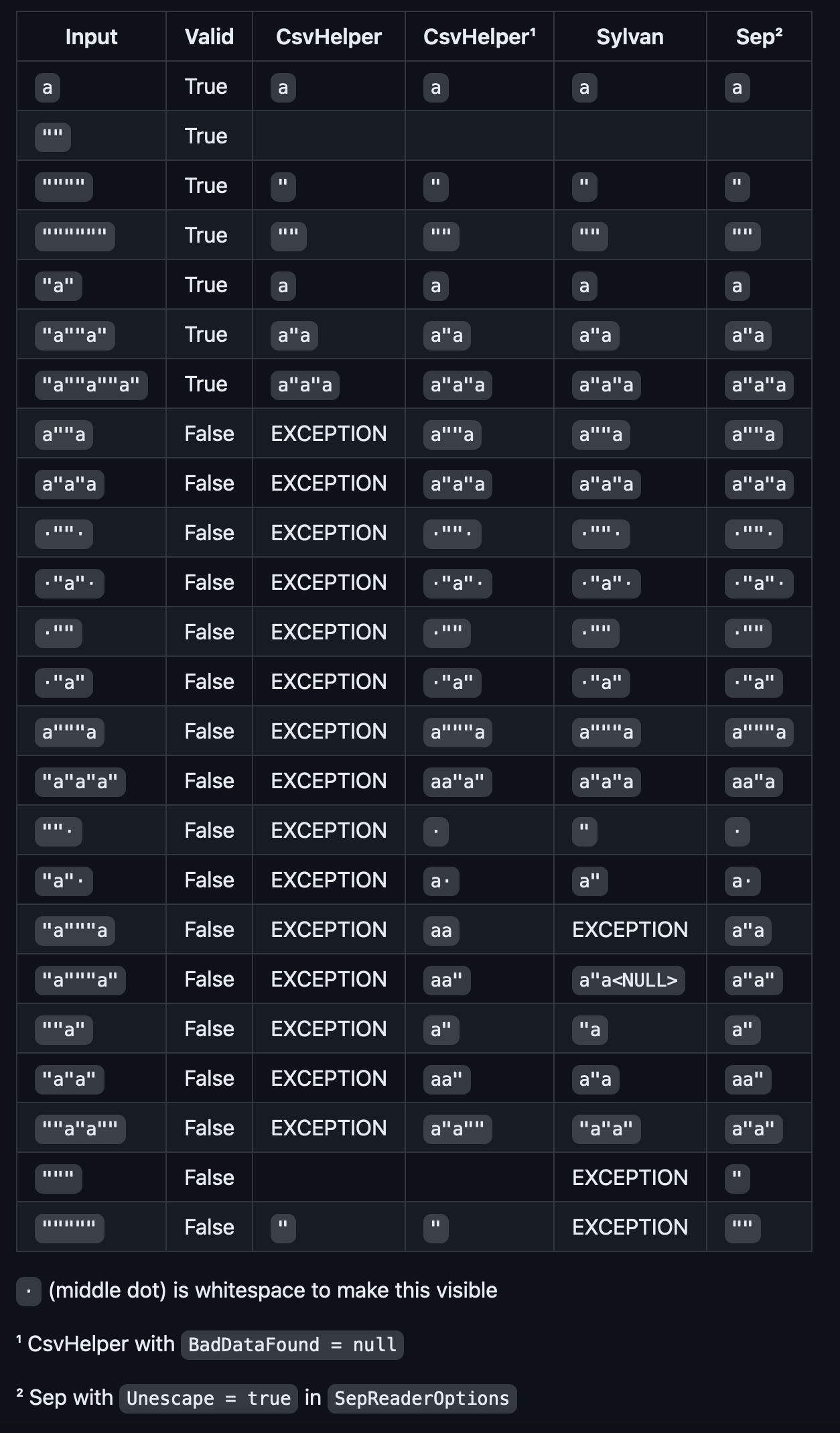
I’ve taken first two columns of this table (without header) and created a test file for both tools to read.
a,True
"",True
"""",True
"""""",True
"a",True
"a""a",True
"a""a""a",True
a""a,False
a"a"a,False
"" ,False
"a" ,False
"",False
"a",False
a"""a,False
"a"a"a",False
"" ,False
"a" ,False
"a"""a,False
"a"""a",False
""a",False
"a"a",False
""a"a"",False
""",False
""""",False
For both I’m using CultureInfo.InvariantCulture and reading without header. Also in both cases input is a string, but for CsvHelper I had to wrap it in StringReader. CsvHelper is using mentioned Mode = CsvMode.NoEscape. And Sep, Unescape = true. Full code is here.
I’m comparing what was read by given library with actual text from the first cell of each row, there’s a pass if values are equal.
Results for CsvHelper:
0: `a` - `a` - Pass
1: `""` - `""` - Pass
2: `""""` - `""""` - Pass
3: `""""""` - `""""""` - Pass
4: `"a"` - `"a"` - Pass
5: `"a""a"` - `"a""a"` - Pass
6: `"a""a""a"` - `"a""a""a"` - Pass
7: `a""a` - `a""a` - Pass
8: `a"a"a` - `a"a"a` - Pass
9: ` "" ` - ` "" ` - Pass
10: ` "a" ` - ` "a" ` - Pass
11: ` ""` - ` ""` - Pass
12: ` "a"` - ` "a"` - Pass
13: `a"""a` - `a"""a` - Pass
14: `"a"a"a"` - `"a"a"a"` - Pass
15: `"" ` - `"" ` - Pass
16: `"a" ` - `"a" ` - Pass
17: `"a"""a` - `"a"""a` - Pass
18: `"a"""a"` - `"a"""a"` - Pass
19: `""a"` - `""a"` - Pass
20: `"a"a"` - `"a"a"` - Pass
21: `""a"a""` - `""a"a""` - Pass
22: `"""` - `"""` - Pass
23: `"""""` - `"""""` - Pass
As you can see it’s a full pass, every row read is exactly as it should’ve been.
Now Sep, which I had to wrap in try/catch as it wasn’t able to read this CSV fully.
0: `a` - `a` - Pass
1: `""` - `` - Fail
2: `""""` - `"` - Fail
3: `""""""` - `""` - Fail
4: `"a"` - `a` - Fail
5: `"a""a"` - `a"a` - Fail
6: `"a""a""a"` - `a"a"a` - Fail
7: `a""a` - `a""a` - Pass
8: `a"a"a` - `a"a"a` - Pass
9: ` "" ` - ` "" ` - Pass
10: ` "a" ` - ` "a" ` - Pass
11: ` ""` - ` ""` - Pass
12: ` "a"` - ` "a"` - Pass
13: `a"""a` - `a"""a,False
"a"a"a",False
"" ,False
"a" ,False
"a"""a,False
"a"""a"` - Fail
14: `"a"a"a"` - `a",False
a"a` - Fail
15: `"" ` - `a"a",False
"` - Fail
Failed at index 16: Found 1 column(s) on row 16/lines [24..25]:'""""",False'
Expected 2 column(s) matching header/first row ''
At index 16 we have an exception, but problems started to occur earlier. Only 7 out of 16 read rows have passed the test of equality. And starting at index 13, Sep completely lost it, you have multiple rows read as a single cell.
This is not to say that Sep is bad, because by all means it isn’t. The data is bad. But unfortunately, I have to work with such data every day. I’m working with output of “tools” written by “devs” for whom f.write("%s,%s" % (string1, string2)) is a proper CSV serialisation, I kid you not. Not to mention people who want to approach everything with regex. But this is a real world.
In a perfect world, where I fully control both input and output, I would go with Sep without a hesitation. But as we still, unfortunately, need Excel, we still need tools like CsvHelper. Which is also a good tool, don’t take me wrong, it’s saved me multiple times, and failed me never. It’s just a bit bloated and hence not so fast, but for a reason. We sometimes need tools which aren’t maybe the fastest, but are helping us make something out of mud.